How Reliable and Consistent Are Kanji Frequency Databases?
Volume 22, Issue 2 (Article 5 in 2022). First published in ejcjs on 17 August 2022.
Abstract
The frequency of usage of a kanji character is a crucial factor in the process of determining which characters to include and which characters to exclude from a textbook. However, the kanji frequency data vary depending on the database we use. As a result, a single database may exclude some characters from a textbook, while the majority of databases would include them. This study attempts to provide a deeper insight into the six popular freely accessible online kanji frequency databases (KFD) and to evaluate how reliable and consistent they truly are. Even though the study has clearly shown a high degree of reliability of the analysed databases, the same cannot be said about the consistency. We found that almost a quarter of all characters in the least consistent database show significant deviation in frequency number. In addition, single-source databases have demonstrated to be less consistent than multiple-source databases, and we also confirmed our hypothesis that the less frequent a kanji is, the more deviated its frequency number tends to be.
Keywords: kanji, Japanese writing system, frequency, database
Introduction
The main goal of this study is to compare six freely accessible databases of kanji usage frequency. Based on the results, we discuss the probable cause for observed discrepancies between the databases. Furthermore, we attempt to estimate the number of characters that may have been heavily affected by those discrepancies and explain why more attention should be paid to the frequency attribute. The overall quality of a frequency database can be determined primarily by the following two factors: reliability and consistency. Given that these two words are not self-explanatory, for the sake of this article, it is first important to clarify both of them. Reliability indicates how close the frequency mean of all kanji within a database is to the average value of frequency means of all databases. Therefore, when there are six different databases, each has its own frequency mean, but all of them also have a combined frequency mean, which is the sum of database-specific frequency means divided by the number of databases (d = 6). The lower the value, the more reliable the database source is. Given our unique kanji dataset, the reliability rate should also indicate how many invaders (kanji whose frequency number is so extremely low that they should not even be included in the list) the dataset contains. Consistency indicates the degree to which the frequency number (FN) of all individual kanji within a database deviates from the frequency mean of all individual kanji from all databases. If we choose a single database, we can evaluate its consistency in just two steps. Firstly, we take a single kanji and look up its FN in the target database. Secondly, we calculate the absolute difference between the FN found in the first step and the average FN of the kanji from all databases. If we repeat this process for every kanji within the target database, we get the consistency mean of the whole database. The lower the value, the more consistent (less deviated) the database is.
The frequency criterion is one of the four main attributes that define any kanji. Generally speaking, every kanji has a certain form, at least one reading, some meaning, and a usage frequency. It can be argued that the usage frequency is the most important of the four, because however simple a kanji may be, we would not feel obliged to learn it if it tends to appear only in ancient and medieval texts. Consequently, Japanese children in primary schools are taught kanji, more or less, according to the frequency of use. This often leads people to claim that the Japanese, in general, learn all kanji according to the frequency order. However, that is barely the case for 1026 kyōiku kanji (kanji for education), which are taught between the first and the sixth grade in primary schools. Afterwards, Japanese secondary school students are usually supposed to learn kanji on an individual basis, and they have much more freedom to choose the order with which they feel comfortable. While it can be argued that it is beneficial to learn the first 1000 kanji according to their usage frequency, the same can hardly be said about learning the rest. It is a well-known fact that the most frequent 1000 kanji cover approximately 90% of all kanji within regular texts (Kanō, 2017). Whether you learn the remaining 10% based on their FN or do not, this will not seriously affect your temporal kanji performance. However, learning things in a chaotic order (i.e., frequency-based order) will almost certainly have a negative effect on long-term kanji retention, whereas using a more systematic order should enable you to remember more characters on a long-term basis, a goal for which probably all of us strive. Thus, it is widely accepted that, for JSL students, mastering all 2136 jōyō kanji (commonly-used kanji) in the official order does not offer any worthwhile benefit whatsoever (Paxton, 2015).
The main danger of ignoring frequency data is that we may end up learning or teaching hundreds of redundant characters of little to no use. Matsushita (2013) correctly pointed out that the vast majority of existing lists of kanji frequencies are too small and too old, or they cover only one domain, such as news, and therefore do not accurately reflect the modern usage of kanji. This may be a serious issue, especially when using a dataset containing more than 1000 kanji. Generally speaking, the less-frequently used kanji are often used in a specific single context. As a result, it is more challenging objectively to evaluate their overall importance, because their FN heavily depends on the database and therefore tends to be more deviated across multiple databases. This study will also clarify whether this is truly the case.
Literature review
As far as we are aware, this is the first study published by a non-Japanese author that includes an extensive comparison of multiple kanji frequency databases (KFD). While there have been several studies on the topic published by Japanese scholars, none of them has such a wide scope as this one. Japanese researchers seem to be primarily interested in the kanji frequency of occurrence in news compared to Websites, thereby limiting the scope of their studies to only two or three sources at most. As a result, the subject of comparison inevitably shifts from the sources themselves to the domains they cover. In our opinion, this is a serious flaw because the sources that cover, for example, the domain of news are often seriously outdated, dating back to the last decade of the previous century. Similar issue can be observed in the case of e-book depositories which are somewhat contaminated by a significant number of old books with obsolete kanji. In the following paragraph, we will mention a few Japanese studies that deal with the kanji usage frequency.
The first two notable studies which should be mentioned are from Shibano (2009) and Nozaki (2012). Both studies were published around the time of the last major revision of the jōyō list in 2010 and both authors used Google kanji frequency data to assess whether those changes were justifiable and whether they truly reflected the actual use on the Internet. Although it is a well-known fact that the scope of consideration for the inclusion of kanji in the jōyō list is significantly broader than electronic Websites, it is undeniable that the Internet is the largest data source and, unlike textbooks, contains elements of the spoken language. After all, it is much easier to collect data from Twitter posts and various Internet forums than from handwritten letters. It is also important to mention one more relatively recent study conducted by Tokuhiro (2018), in which the author compares the frequency data of 3000 kanji as they appear in the Mainichi newspaper articles and on the Internet Websites. In spite of the fact that the study makes use of the recently accessed NWJC (NINJAL Web Japanese Corpus) data source, it suffers from a major drawback due to the use of outdated Mainichi newspaper source that traces back to the previous century, specifically the period between 1985 and 1998. Given that the Internet was not particularly popular back then, it can be argued that it is not a fair comparison, one of the reasons being the different number of jōyō kanji within the official list.
We did not manage to find a research paper which would analyse the kanji frequency databases, and which would be written by a non-Japanese author. Several people performed a statistical analysis of some sort on a particular dataset, but neither of them compared multiple KFD and attempted to draw upon the results. From our perspective, this is a serious gap within the research area because, as we seek to demonstrate in this study, various databases dispose of various quality of data. Therefore, while it is perhaps interesting to compare the kanji frequency of occurrence in different domains, we would argue that those results are relatively predictable, and it is more useful to compare the sources themselves.
Methodology
The main objective of this study was to calculate and compare the reliability and consistency rate of six free-to-use kanji databases. We opted to use two different methods—the simpler one for the reliability rate and the more intricate one for the consistency rate. Nevertheless, in both cases, we were mainly interested in standard deviations of the database-specific frequency mean from the combined frequency mean.
Reliability rate
The reliability rate is calculated as follows: find the average FN for each of the six databases and calculate their combined average FN by adding the average FN for each database and dividing it by the total number of databases (d = 6). Subsequently, calculate the variance and standard deviation. If any database deviates > 2σ (two times the standard deviation), it is unreliable, and if any database deviates > 1σ, its reliability is questionable. In short, the lower the number, the more reliable the database.
Consistency rate
The consistency rate is calculated as follows: firstly, find the absolute difference between the FN of a kanji within a database and the average FN for that kanji across all six databases and repeat this process for every kanji in every database. Secondly, calculate the average difference for each of the six databases and find the database with the lowest deviation mean. Thirdly, calculate the variance and standard deviation. Fourthly, divide the standard deviation of the database by the average standard deviation for all databases and repeat the process for each database. Lastly, confirm the results by performing one-sample t-test against a known mean six times (for each database) with the following null hypothesis: ‘there is no significant difference between the database mean and the lowest deviation mean’ and the level of significance = .05. If any database deviates > 2σ, it is considered inconsistent, and if any database deviates > 1σ, its consistency is questionable.
Kanji frequency databases
For the purpose of this study, we selected six popular online kanji frequency databases (KFD) that are freely accessible online—Matsushita’s Character Database, Kanji Usage Frequency, Kanji Database, Kanji Frequency List (漢字出現頻度表) published by the Japanese Agency for Cultural Affairs (文化庁), Yatskov’s Wikipedia Kanji Frequency Report and the KANJIDIC2 frequency list from the popular Web site jisho.org. The differences between these sources are shown in Table 1.
 * the number for the smallest domain (online news), other three domains contain more
* the number for the smallest domain (online news), other three domains contain more
** even though the database contains over 13000 characters, jisho.org lists only 2500 kanji
Table 1 An overview of analysed KFD
It is also necessary to mention the sources these databases utilise in order to retrieve frequency data. They are provided in Table 2 below.
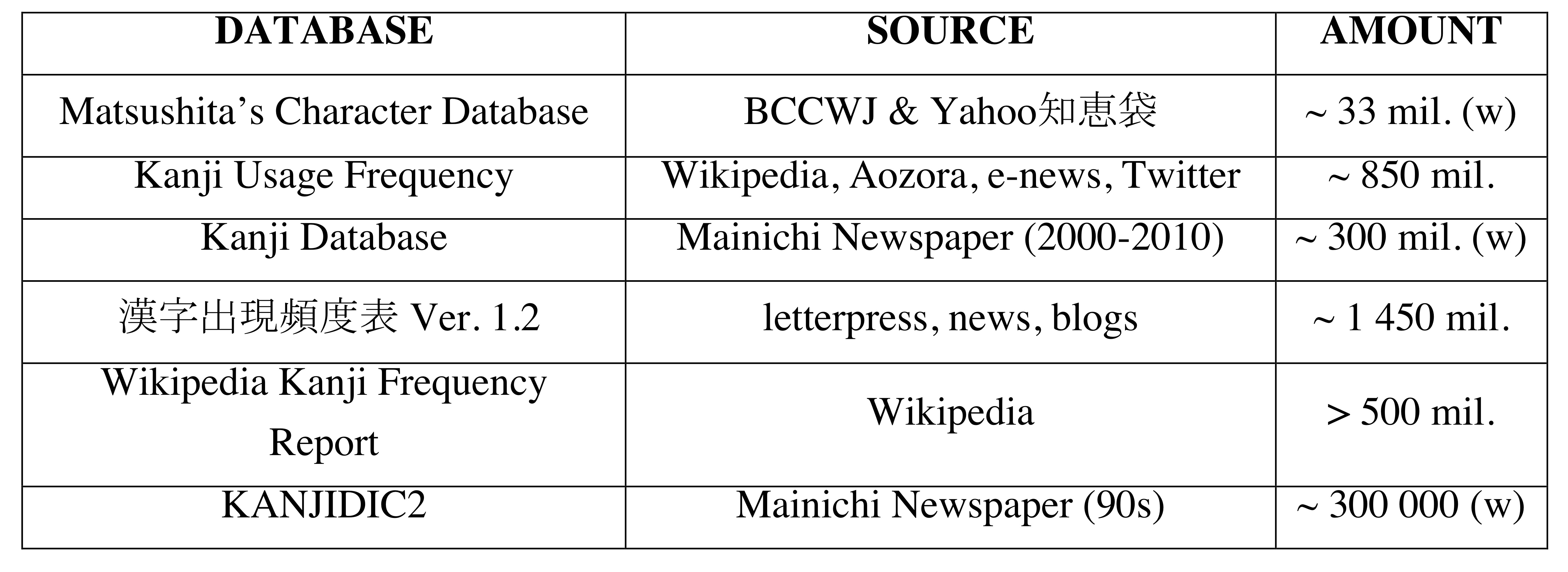 Table 2 Source materials of selected KFD
Table 2 Source materials of selected KFD
Given the information that the authors provide, it is clear that the largest amount of data was processed for KFL (漢字出現頻度表 Ver. 1.2) published by the Japanese Agency for Cultural Affairs, whereas the smallest amount was used for KANJIDIC2. Nevertheless, it is important to emphasise that the quantity does not necessarily reflect the quality; therefore, we should avoid jumping to conclusions based solely on the size of the source material. What is more, while some authors provide information about the amount of data in characters, others provide them in words. Consequently, it is difficult to compare the amount of source material of, for instance, KD and KUF, because we would also need to take into consideration the specific parsing methods that KD used to retrieve data. In order to be able to apply data to a flexible ordering system that, unlike the standard jōyō kanji list, utilises the frequency criterion, we decided to take the list of 2000 kanji (identical to the MBO ver. 5.7) and looked up their frequency numbers across all six databases. Naturally, we had to deal with several issues that were inevitably intertwined with the intrinsic nature of the available data.
First of all, since some databases contain a relatively low number of characters, in some cases, we were unable to find the frequency data for the kanji from our list of 2000 characters. However, to avoid missing data, we opted to fill these blanks with the provisional FN whose value is based on the kanji count of the database. The exact numbers are provided in Table 3.
 Table 3 The list of provisional FN
Table 3 The list of provisional FN
Secondly, it is important to note that the first two databases (MCD and KUF) encompass frequency data from several different domains. The data they contain are the average values that were calculated by summing up FN from all domains and dividing the product of sum by the total number of covered domains. As a result, there is no kanji with FN = 1, as it would have to be the most frequent character in the majority of domains. This is especially important when assessing the frequency means of these two particular databases. Given that both of them utilise multiple domains, their frequency means are expected to be above average. In the case of KUF, the difference should be almost negligible, but in the case of MCD that contains more than ten different domains, the difference may be even around +100. Therefore, if we speak of the 1000 most frequent kanji from MCD, we talk about characters whose FN is within the range from 28 to roughly 1100. Due to issues related to the normalisation of the frequency data, it was not possible to avoid this limitation while fully maintaining analytical objectivity. Consequently, as far as the reliability rate is concerned, we can only estimate that MCD should still be considered at least somewhat reliable, if its deviation spans between 75 and 125, and it could be considered reliable if the deviation is in the range from 90 to 110. It is necessary to mention that this discrepancy should not seriously affect the consistency rate of the database.
Thirdly, it is highly unlikely that the MBO list ver. 5.7 contains all 2000 most frequent characters. Consequently, it makes sense why the combined average FN has to be higher than 1000, as some kanji in our list simply do not belong to the 2000 most frequent ones. Finally, it should also be mentioned that databases tend to exclude kanji used in personal names, but they often include kanji used in names for places, cities, or towns. The most recent addition of 20 kyōiku kanji used in the names of prefectures (Tonooka, 2018) suggests that it is perhaps worthwhile to learn some additional characters, even if they are rarely used (even though the character 阜 for Gifu Prefecture and 滋 for Shiga Prefecture are not even included in our 2000 kanji list, because of their extremely low frequency of use).
Results
Reliability rate
Given the number of kanji (k = 2000) in our dataset and the intrinsic nature of utilised databases, we expected the joint average FN to be slightly above 1000, and this is indeed the case. The combined average FN for all databases is 1064, with Kanji Database having the lowest value of 1026 and Matsushita’s Character Database having the highest value of 1161. The high FN of MCD was predicted due to the number of domains that the database covers. Therefore, it can be said that all six databases proved to be reliable, although it is difficult to assess how reliable MCD really is. Reliability data is shown in Table 4.
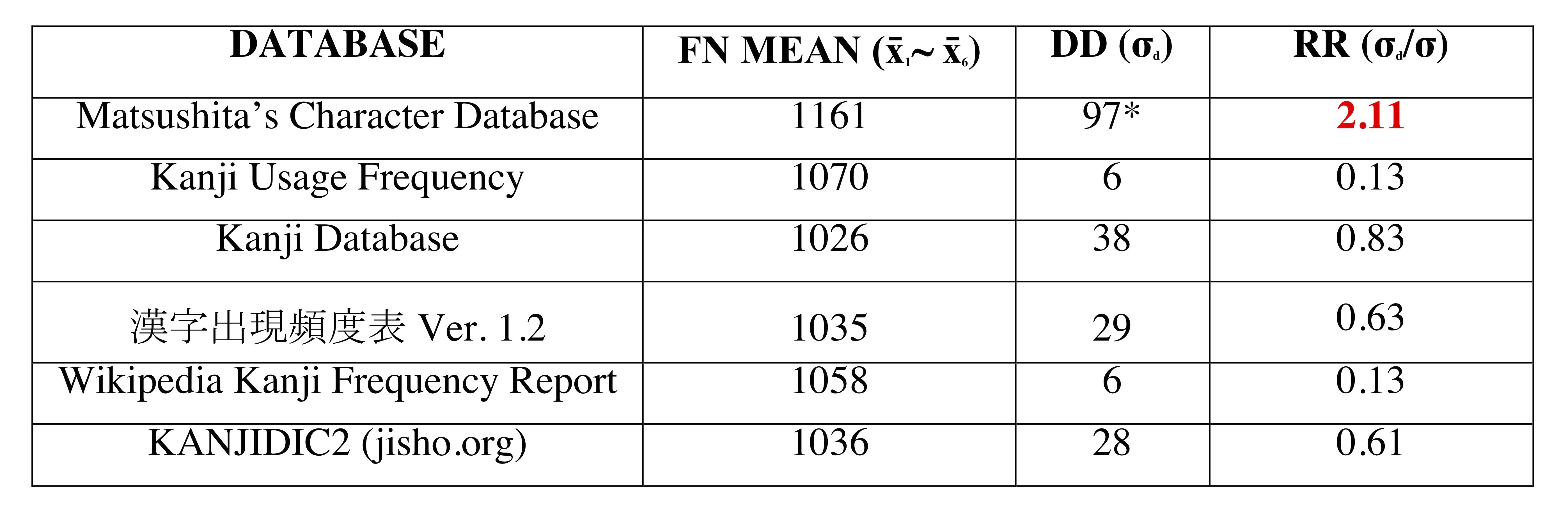 Table 4 Reliability data
Table 4 Reliability data
* the deviation is extremely close to our predicted deviation of 100
Table 4 suggests that five databases are reliable (although KD is close to somewhat reliable) and one database, that is, the MCD, is unreliable (RR > 2.00). However, bear in mind what we mentioned previously about MCD—if we were to normalise its kanji FN, it would have been classified as reliable.
Consistency rate
The consistency rate was much harder to predict than the reliability rate. The combined difference mean for all databases was 151—the minimum (min = 113) achieved by KUF and the maximum (max = 207) attained by WKFR. We also would like to mention that we managed to verify the calculated consistency rates by conducting six individual t-tests (with the tabulated f-value = 2.015). However, we decided not to include critical f-values in the table, as they only reflect the data already provided. All relevant data are available in Table 5.
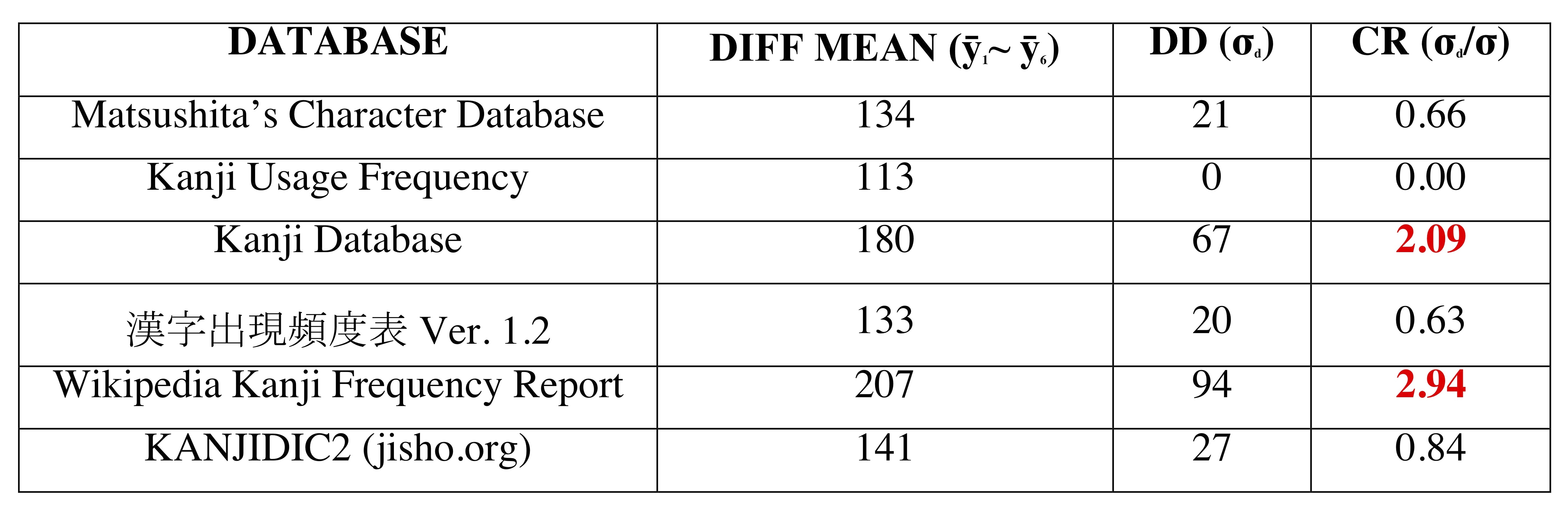 Table 5 Consistency data
Table 5 Consistency data
Table 5 suggests that four databases are consistent and two databases are inconsistent. However, this statement alone does not tell us anything about how these inconsistencies reflect in practice. Thus, we decided to find out how many characters in each database deviate from the average FN by more than 300, 400, 500, and 600. The results are shown in the bar charts below.
Figure 1 The number of characters with FN deviation spans > 300
As we can see in Figure 1, the number of kanji roughly doubles each time we move by 100. The only significant exception to this pattern is when we move from diff > 400 to diff > 300 in the databases MCD and KUF. The number of deviated kanji is more than tripled (from 56 to 181 for MCD and from 30 to 108 for KUF). However, these two databases still remain the most consistent, so we will focus on the two least consistent databases instead. Detailed data on KD and WKFR are shown in Table 6.

Table 6 The number of kanji with specific FN deviation spans in KD and WKFR
If we thoroughly think about the data from Table 6, we can reach several interesting conclusions, but probably the most intriguing one is that almost a quarter of all kanji from WKFR and almost one-fifth of all kanji from KD are deviated by more than 300 from the average FN. Therefore, if we created a list of 2000 kanji based on the frequency data from WKFR, it would most likely not contain as many as around 75 kanji that should be included in it according to a more accurate frequency source. Furthermore, it would also contain around 75 kanji invaders that should not be there, because their FN is in fact higher than 2000. Even though 150 out of 2000 characters may not seem substantial, bear in mind that it is a more conservative estimate because we can also assume that only a negligible number of kanji from the top 500 frequent characters have FN deviation higher than 300, and therefore a more realistic estimate would be about 200 kanji instead of 150. Once again, 200 out of 2000 may seem acceptable, but it is important to point out that if a student is truly devoted to learning all of the 2000 most frequent characters and they find out that 200 characters they have learned do not belong to the 2000 most frequent ones, they still have to learn additional 200 characters.
In the case of KD, the numbers are slightly more acceptable. There are around 120 kanji invaders that should not be included in the list of 2000 kanji. Nevertheless, it can be argued that the inconsistency rate is still relatively high, and we would definitely not recommend using this kanji frequency database as the primary source for creating educational materials.
We would like to point out that, from our point of view, not enough attention is paid to the frequency attribute. Many authors of textbooks often prefer simply to include all kanji from the jōyō list rather than using a kanji database to determine a few hundred characters that could be excluded with minimal diminishing returns. The Japanese themselves seem to be unwilling substantially to revise the jōyō list, despite making a few changes here and there. This does not mean that we call for the abolishment of the jōyō list, because there are numerous arguments for its existence. However, there is no reason why, in its current form, it should be held dear by foreign teachers and scholars producing kanji textbooks. Instead, we would advise them to think of the jōyō list as the upper limit of the number of kanji that should be included in any teaching material, because at a certain point it is more efficient to learn words instead of kanji (Tokuhiro and Kawamura, 2007). Learning and remembering hundreds of kanji is a daunting task itself, and while it is true that if students are able to overcome a certain threshold, the task becomes much easier, it can also be assumed that they would be capable of remembering kanji more firmly if they were not required to learn additional hundreds of characters of little to no use. In this regard, it would perhaps be intriguing to conduct an experiment that would reveal whether advanced students of Japanese make more mistakes in the kanji with the FN, for example, above 1500, or in the kanji with the FN between 1000 and 1500.
It is also vital to point out that all three least consistent databases (CR = 2.94, 2.09, and 0.84) utilise a single source material, whereas all three more consistent databases utilise multiple source materials. The positive effect of using multiple sources can be clearly observed if we compare WKFR and KUF, as both of them use frequency data gathered from Wikipedia by bots. What makes KUF a much more consistent database than WKFR is not the quality of bots, but the fact that it also makes use of three additional sources. This does not necessarily mean that a single source database is always less consistent than a multiple source database (after all, KD is almost as consistent as MCD), but it is apparently useful to gather data from at least a couple of different domains. Consequently, we believe that scholars should pay more attention to comparing multiple databases and draw conclusions based on their contrastive characteristics rather than focusing on a single domain or a couple of domains and explaining why their preferred one is better than the other.
Last but not least, we also managed to verify our assumption that kanji with lower FN have smaller frequency deviations than kanji with higher FN. We observed 20 randomly selected characters from each of the three different population samples: a) average FN < 750, b) average FN between 750 and 1500, and c) average FN > 1500. The results are shown in Figure 2 and clearly suggest a correlation between FN and FN deviation.
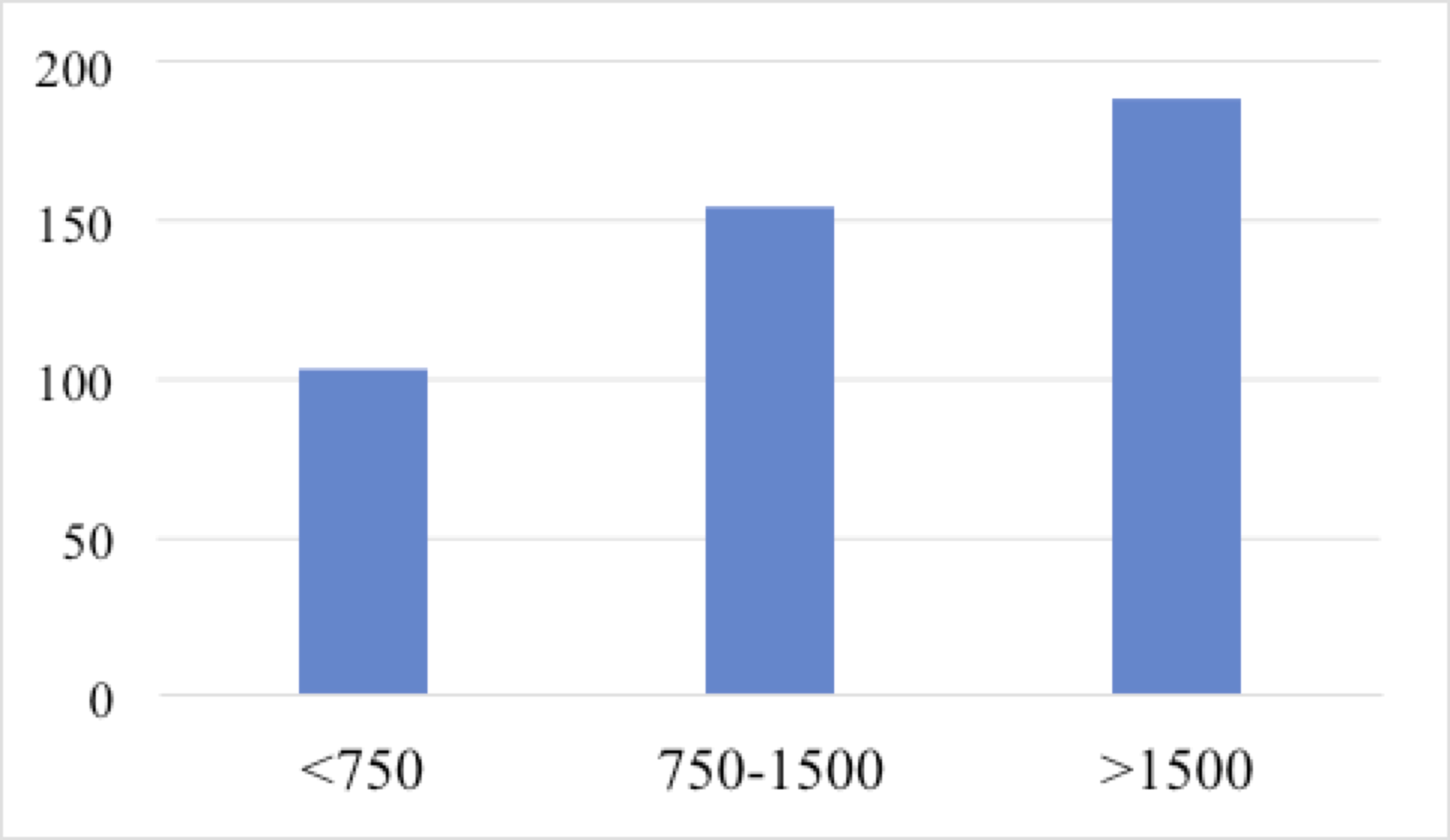
Figure 2 Average FN deviation for kanji within different frequency spans
Conclusion
The study revealed that all six databases are reliable, but only four are truly consistent. Kanji Database can only be considered borderline between somewhat consistent and slightly inconsistent. Given that we opted to use rather conservative estimates, it can be argued that both databases are not suitable for creating frequency-based learning (or teaching) materials. On the other hand, the Kanji Usage Frequency database seems to be the most consistent, in fact almost five times more consistent than the WKFR (for kanji with FN deviation > 300).
We also demonstrated that characters with high FN (FN > 1500) have, on average, almost double the FN deviation compared to characters with low FN (FN < 750). Therefore, the larger the kanji dataset we use, the more aware we should be about which kanji it contains, as we may end up including dozens of redundant characters. The fact that the official jōyō list suffers from this very drawback is well-known, and most teachers prefer to teach students only up to around 1500 characters because the rest can be picked up by learning individual words rather than kanji themselves.
Based on the results of this study, we published a freely available kanji frequency list of 2000 characters that includes the optimised data from all six databases. It is extremely important to be able to access a source like this—not only for educational purposes but also for self-study purposes. Furthermore, we have also published an updated version that incorporates data from the largest frequency source (Google) published by the Japanese scholar Shibano Kōji (2009). The updated list contains additional 242 jōyō kanji that are not included in the list of 2000 kanji, and it is also freely accessible on the Internet through the ResearchGate Website.
References
Bunkachō (Agency for Cultural Affairs). 2010. Kanji shutsugen hindohyō jun’i taishōhyō (The Contrastive List of Kanji Frequency Numbers). https://www.bunka.go.jp/seisaku/bunkashingikai/sokai/sokai_7/45/pdf/besshi_1.pdf
(accessed 26 Nov 2021).
Kanō, Ch. 2017. Kanjiken gakushūsha to hikanjiken gakushūsha no tame no kanjigakushū to hyōka no hōhō: onsei to hyōki wo musubitsukeru katsudō no kokoromi (Evaluation Methods for Kanji Background and Non-Kanji Background Learners: Attempt to Combine Sound and Orthography). JSL Kanji Learners’ Research Bulletin 9: 1-10. https://doi.org/10.20808/jslk.9.0_1 (accessed 27 Dec 2021).
Matsushita, T. 2011. Vocabulary Database for Reading Japanese (version 1.1). http://www17408ui.sakura.ne.jp/tatsum/english/databaseE.html#vdrj (accessed 24 Nov 2021).
Matsushita, T. 2013. Gendai nihongo moji dētabēzu (The Database of Modern Japanese Characters). http://www17408ui.sakura.ne.jp/tatsum/database.html#cdj (accessed 24 Nov 2021).
Nozaki, H. 2012. Jōyō kanjihyō kara sakujosareta kanji no jisho keisai jōkyō no bunseki (Analysis of the Dictionary Data on the Kanji Removed from the Jōyō List). https://aue.repo.nii.ac.jp/?action=repository_uri&item_id=1328&file_id=15&file_no=1 (accessed 16 March 2022).
Paxton, S. R. 2015. Tackling the Kanji Hurdle: An investigation of kanji order and its role in facilitating the kanji learning process. Australia: Macquarie University. https://doi.org/10.5861/ijrsll.2013.519 (accessed 22 Nov 2021).
Shpika, D. 2016. Kanji Usage Frequency. https://scriptin.github.io/kanji-frequency/
(accessed 23 Nov 2021).
Shibano, K. 2009. Shinjōyō kanjihyō no tame no kanji shutsugen hindo chōsa (The Survey of Kanji Usage Frequency for the New Jōyō Kanji List). https://sites.google.com/site/shibano/shin-jouyoukanji-hyou-no-tame-no-kanji-shutsugen-hindo-chousa (accessed 3 Dec 2021).
Tamaoka, K. et al. 2015. The new 2136 Japanese Jōyō kanji web-accessible database. https://www.kanjidatabase.com/ (accessed 25 Nov 2021).
Tokuhiro, Y. and Kawamura, Y. 2007. Kanji 2100-ji no tangosū chōsa to tango ichiranhyō no sakusei (Quantitative Study on the Vocabulary of 2100 Kanji Characters and the Compilation of the Vocabulary List). The Japanese Language Education 1: 1-10. ISSN 1882-3394. (accessed 26 Dec 2021).
Tokuhiro, Y. 2018. Kanji 3000-ji no webu nihongo saito shutsugen hindo chōsa (The Survey of Kanji Usage Frequencies of 3000 Characters from Japanese Websites). https://eaje.eu/pdfdownload/pdfdownload.php?index=539-540&filename=poster-tokuhiro.pdf&p=Lisbon (accessed 16 March 2022).
Tonooka, H. 2018. Kata, hime nado shōgaku kanji 20-ji tsuika, kenkyū no ikō sochi taiō kyōzai (The Reform by Gakken Regarding Transition to Appropriate Teaching Materials Sees the Addition of 20 Elementary Level Kanji, Such As Lagoon and Princess). https://resemom.jp/article/2018/03/29/43792.html (accessed 28 Dec 2021).
Yatskov, A. 2010. Wikipedia Kanji Frequency Report. https://foosoft.net/posts/kanji-frequency/ (accessed 26 Nov 2021).
Article copyright Patrick Kandrac.
The electronic journal of contemporary japanese studies was founded on 9 January 2001.
Page created 16 December 2019, last modified 16 December 2019.
Email the webmaster if you have any problems.
Copyright electronic journal of contemporary japanese studies.
